|
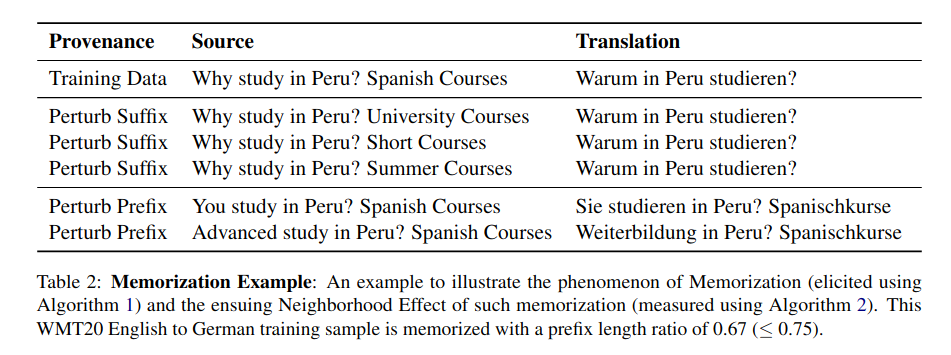
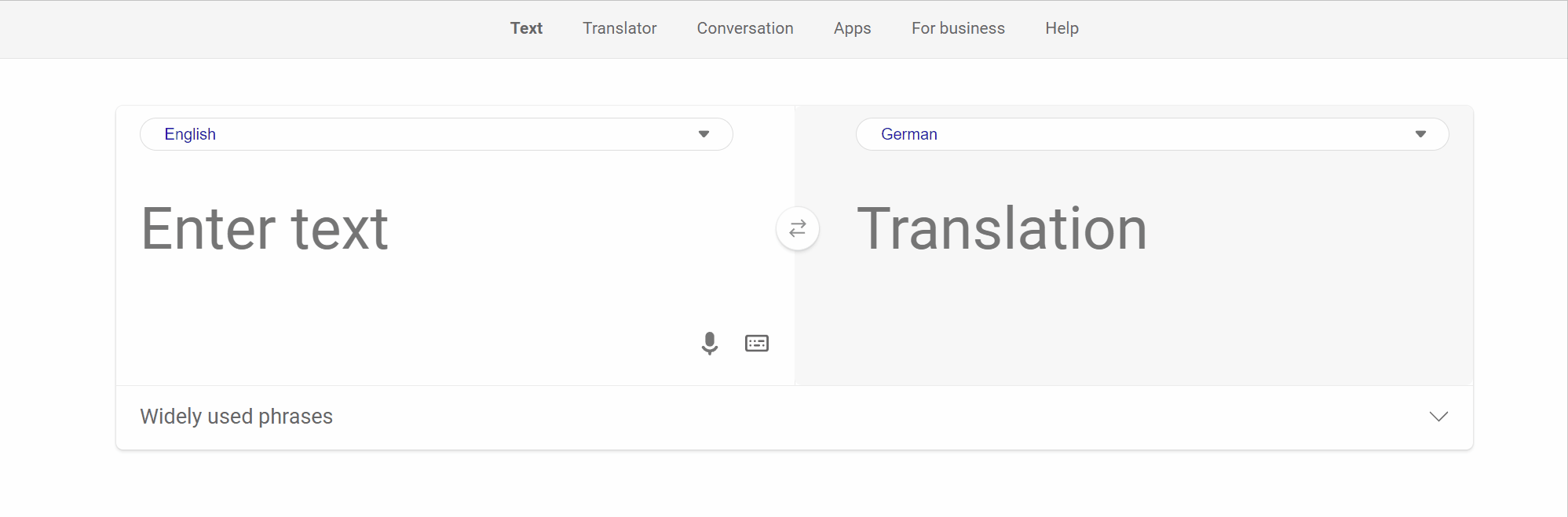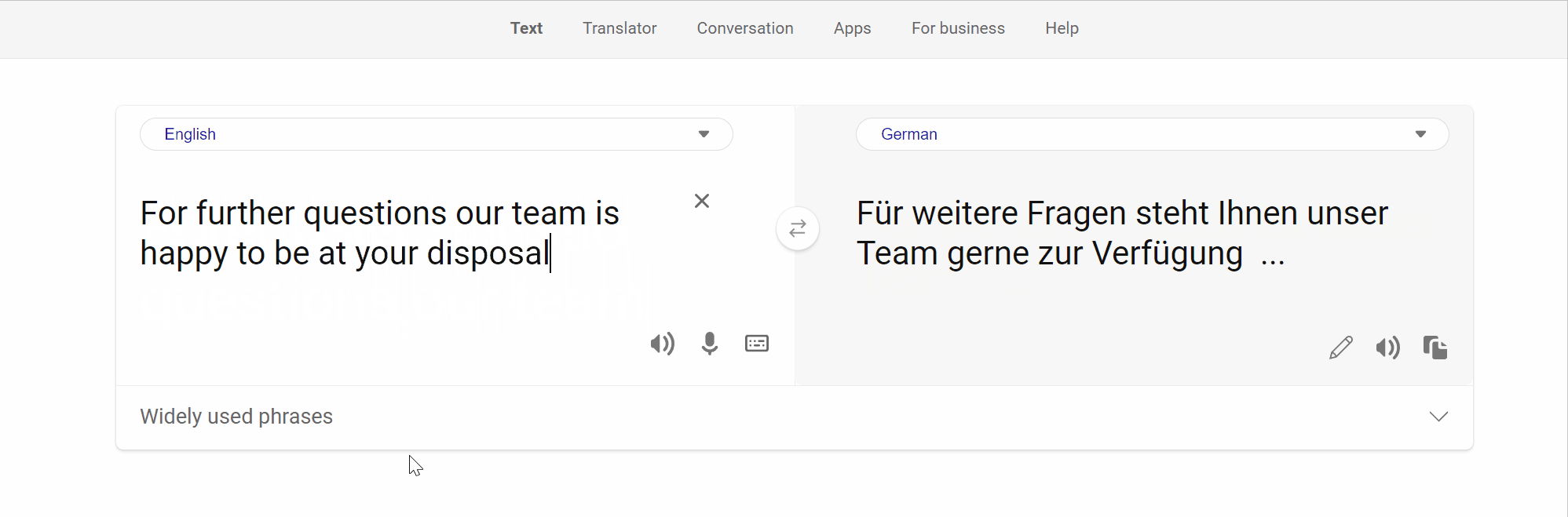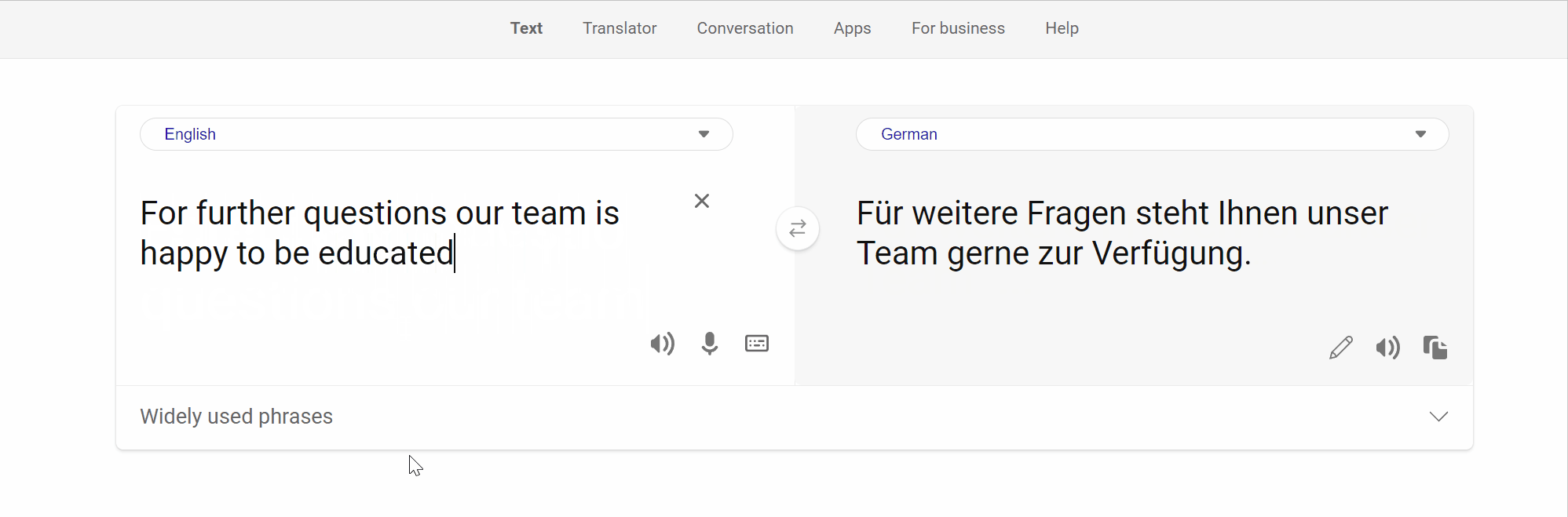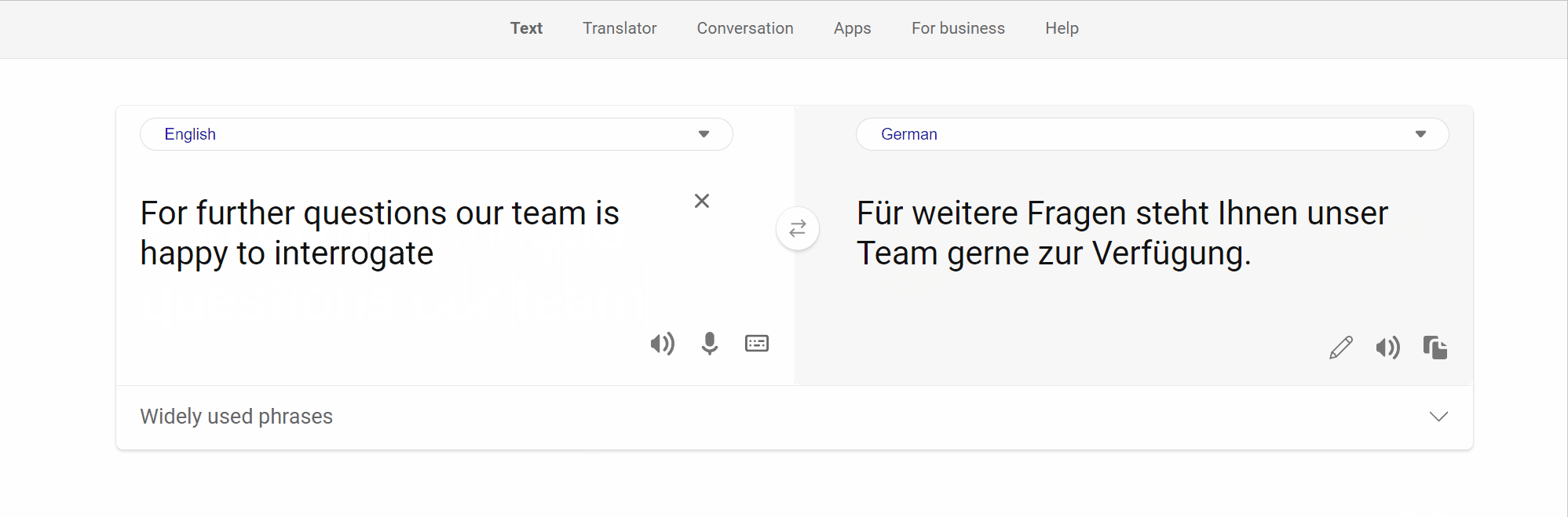
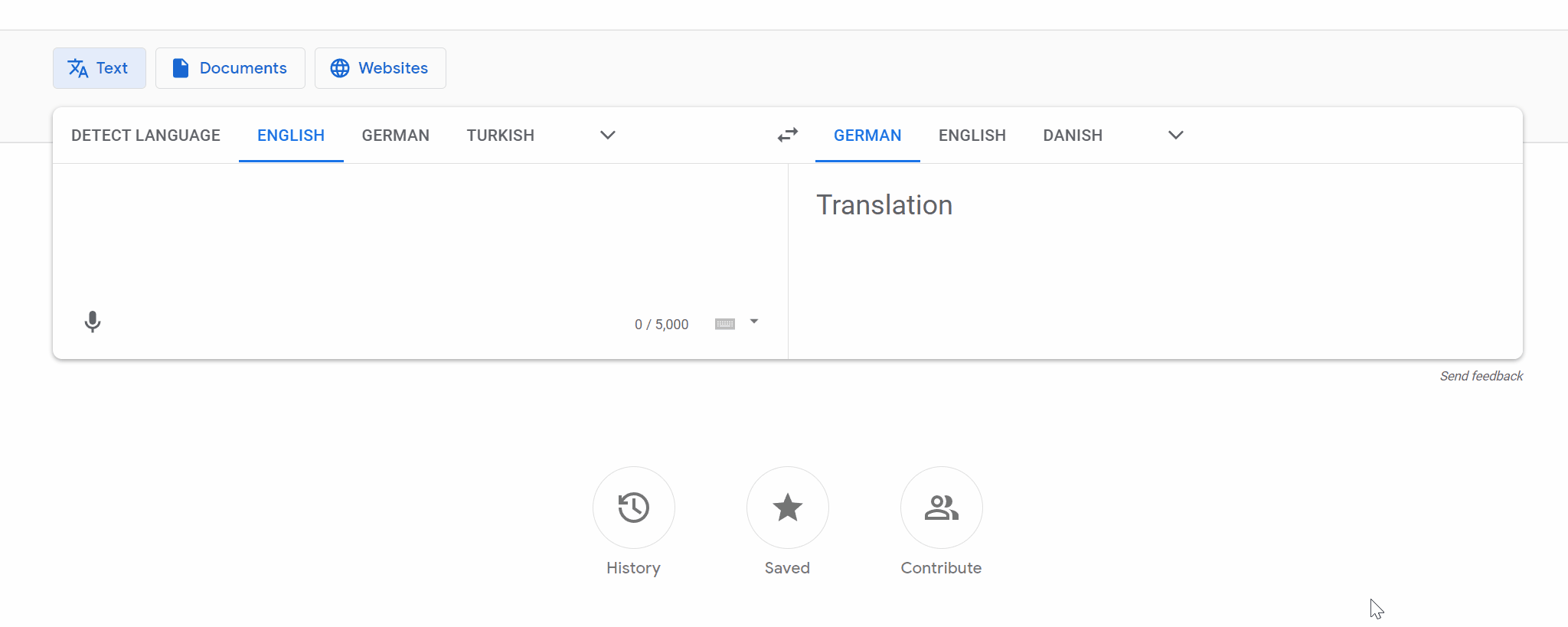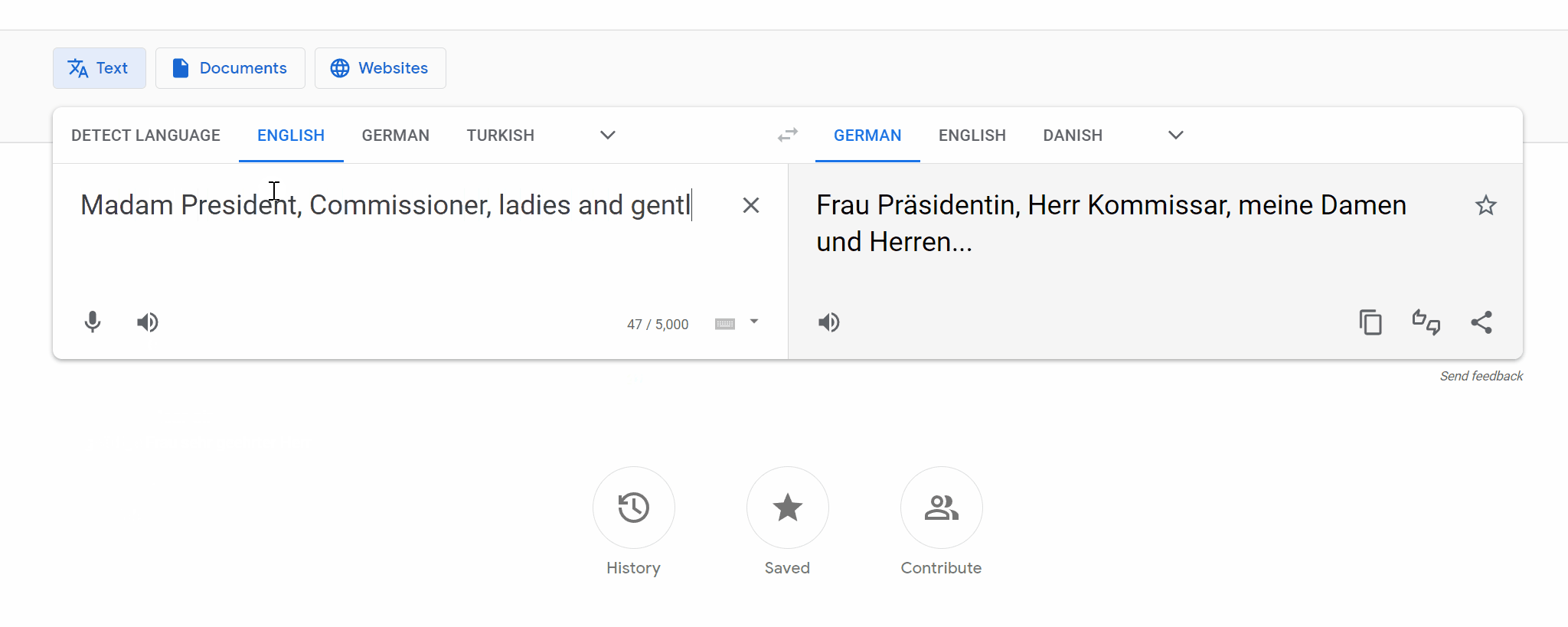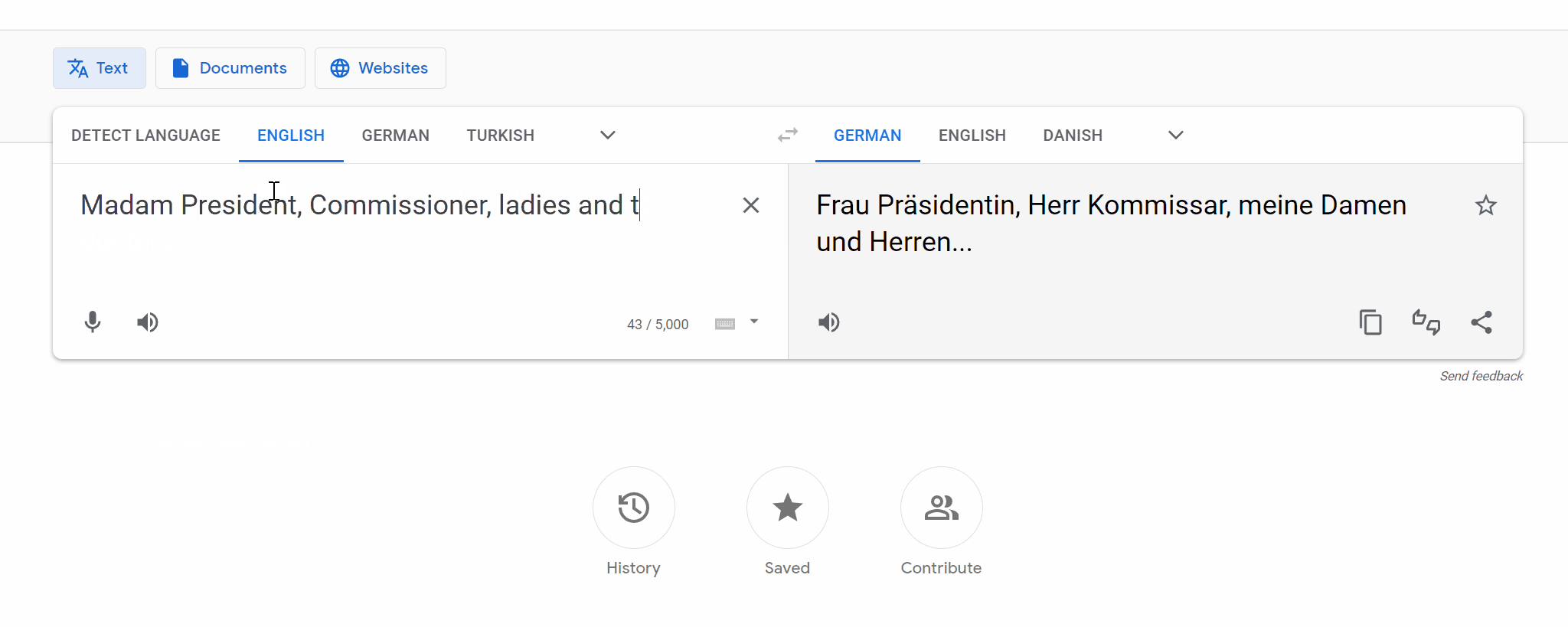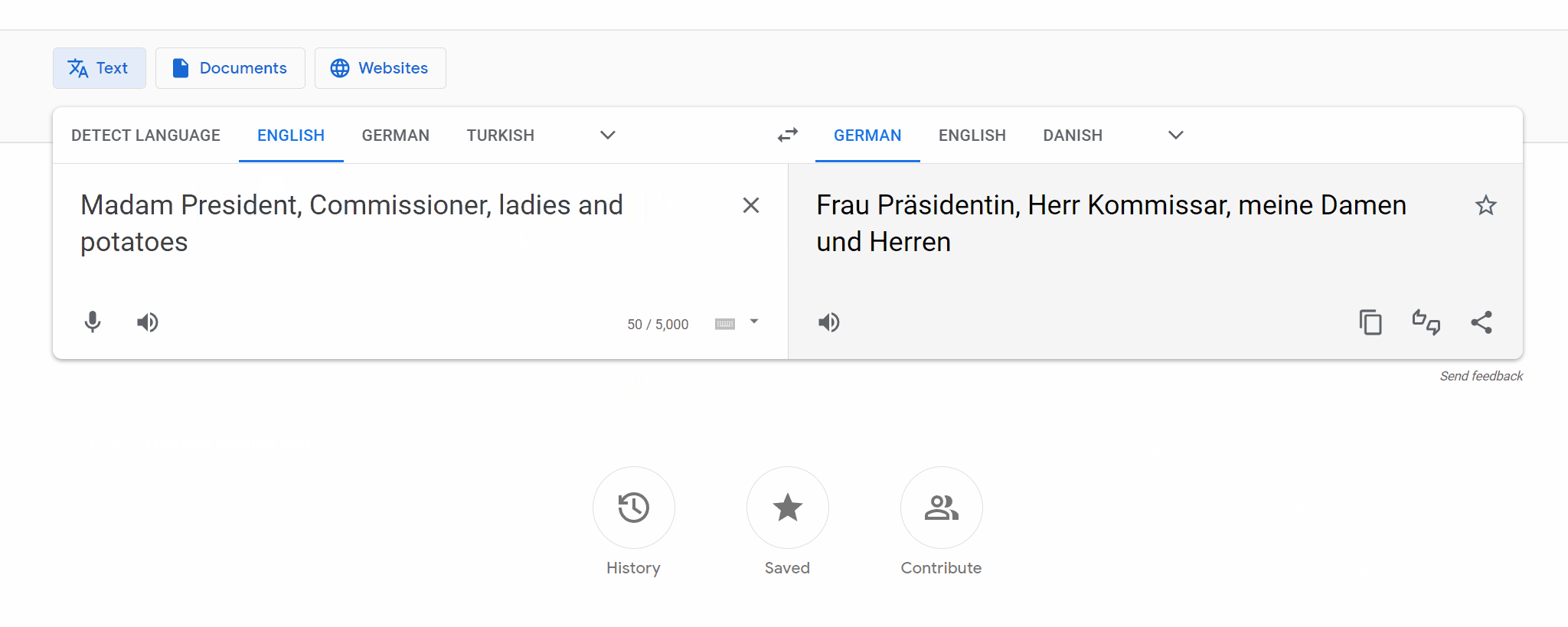
Memorization presents a challenge for several constrained Natural Language Generation (NLG) tasks such as Neural Machine Translation (NMT), wherein the proclivity of neural models to memorize noisy and atypical samples reacts adversely with the noisy (web crawled) datasets. However, previous studies of memorization in constrained NLG tasks have only focused on counterfactual memorization, linking it to the problem of hallucinations. In this work, we propose a new, inexpensive algorithm for extractive memorization (exact training data generation under insufficient context) in constrained sequence generation tasks and use it to study extractive memorization and its effects in NMT. We demonstrate that extractive memorization poses a serious threat to NMT reliability by qualitatively and quantitatively characterizing the memorized samples as well as the model behavior in their vicinity. Based on empirical observations, we develop a simple algorithm which elicits non-memorized translations of memorized samples from the same model, for a large fraction of such samples. Finally, we show that the proposed algorithm could also be leveraged to mitigate memorization in the model through finetuning. We have released the code to reproduce our results at https://github.com/vyraun/Finding-Memo.
|